By Group "DeepText Analysts"
The Digital Gold Rush: Why Cryptocurrency Analysis Matters Now
Our team, DeepText Analysts, is investigating whether natural language processing (NLP) can predict cryptocurrency performance, with a specific focus on TerraLuna. This research carries significant implications due to the cryptocurrency industry's explosive growth, increasing mainstream adoption by businesses, persistent market volatility, and the need for better investment decision support tools.
The intersection of NLP and cryptocurrency markets represents a promising frontier in fintech research, with practical applications for risk management and investment strategy development in this rapidly evolving but highly unpredictable financial landscape.
By applying sentiment analysis to social media discussions and other information sources, we aim to develop models that might forecast crypto market movements. The dramatic collapse of TerraLuna serves as our central case study, raising the question: Could sentiment analysis have provided early warning signals before the crash?
About TerraLuna
TerraLuna is a decentralised blockchain platform containing TerraUSD, an algorithmic stablecoin that was backed by LUNA, a native token which provides an arbitrage opportunity by absorbing the short-term volatilities of TerraUSD. TerraUSD’s unique concept of securing stability with LUNA instead of normal asset reserves appeared successful as the 8th largest market capitalisation in cryptocurrency in April 2022. Luna’s sudden crash on May 9th, 2022 was caused by over $2 billion worth of UST being unstaked which depegged the stablecoin and caused crypto exchanges to delist LUNA and UST pairings. This made LUNA worthless, resulting in significant consequences to the highly volatile cryptocurrency market and Luna investors.
Due to TerraLuna’s strong past performance, the company’s loyal fans, known as Lunatics used to frequently share their thoughts and discussions on Reddit. Thus, given the copious amount of available data and the complete price history on the growth and downfall of TerraLuna, we plan to use this information to train our model which we hope can analyse and predict cryptocurrency performance based on public sentiment on other cryptocurrencies.
Our Methodology
To start our data workflow, we have carefully considered the various types of data sources to establish as our foundational framework. We have structured our thought process around several key factors: the nature of the data source, the category of cryptocurrency, and the timeline of our data, and the methodology we employ to measure sentiment analysis. Each of these elements plays a critical role in ensuring the robustness and accuracy of our research.
Firstly, with our data source, we decided to start working on Reddit posts, an online social media platform which offers a rich database on a diverse range of topics. We chose to focus on the comment section which makes it particularly easy to find insightful discussions and news articles related to cryptocurrency, especially on the subject of TerraLuna. Next, we established a specific timeline for our data collection, focusing on posts from the year 2020, when cryptocurrency was gaining popularity, to 2022, just prior to the collapse of TerraLuna. With this timeframe, we can properly evaluate whether our results align with the actual historical outcomes of the cryptocurrency market, ensuring the relevance and accuracy of our analysis.
Taking all these factors into account, this serves as our foundational base case. Our product is designed to offer flexibility, enabling the application of this methodology to any cryptocurrency by leveraging diverse data sources and analytical approaches, such as dictionary-based methods, deep learning techniques, or Python packages. Once our system is established using this base case, we will expand our exploration to incorporate a variety of scenarios and methodologies.
Breaking the Code: Our Multi-Faceted Approach to Crypto Prediction
Model 1: Dictionary-Based Sentiment Analysis
We're analyzing thousands of Reddit threads related to TerraLuna using lexicon-based sentiment analysis techniques. This approach leverages the Loughran-McDonald Dictionary, which was specifically developed for financial text analysis and captures finance-specific terminology that general sentiment dictionaries often misclassify. The dictionary categorizes words into six sentiment categories (positive, negative, uncertainty, litigious, strong modal, and constraining), allowing us to detect nuanced financial sentiment beyond simple polarity. Each comment is processed to extract these specialized sentiment metrics, enabling us to track shifts in investor confidence, uncertainty, and regulatory concerns within the TerraLuna community over time. We're particularly focused on identifying sentiment patterns that preceded major price volatility during the collapse.
Model 2: Advanced Deep Learning Architecture
We're developing sophisticated neural network models—including BERT (Bidirectional Encoder Representations from Transformers) and FinBERT (Financial domain-specific BERT)—that can capture nuanced relationships between language patterns and market movements. These transformer-based models excel at understanding context and can be fine-tuned on cryptocurrency-specific language. Unlike dictionary methods, these approaches can recognize complex linguistic patterns, sarcasm, and emerging terminology common in crypto communities.
Potential Additional Methods to Explore
Topic Modeling with LDA (Latent Dirichlet Allocation)
By implementing topic modeling, we could identify emerging discussion themes that correlate with market shifts. This would help us understand not just sentiment polarity but the specific concerns driving community reactions.
Time Series Forecasting with LSTM Networks
Long Short-Term Memory networks could help us better model the temporal dynamics between sentiment shifts and price movements, accounting for both immediate and delayed effects.
Hybrid NLP-Technical Analysis
Combining our NLP insights with traditional technical indicators (RSI, MACD, Bollinger Bands) could yield a more comprehensive prediction model that considers both market psychology and price action patterns.
Transfer Learning from Related Assets
We could explore transfer learning techniques to leverage patterns discovered in other cryptocurrencies to enhance our TerraLuna predictions, potentially identifying universal sentiment indicators across the crypto market.
Named Entity Recognition for Key Influencers
Implementing named entity recognition could help us identify and track key influencers whose opinions disproportionately impact market sentiment and price movements.
Current Progress
Our data collection phase has been fascinating. We've gathered Reddit discussions about TerraLuna. This code shows how we used the Reddit API for data collection:
import praw
import pandas as pd
import openpyxl
import datetime
# initialize Reddit API
reddit = praw.Reddit(
client_id='ZExuVDrnuon1q8SWA__2fw',
client_secret='TENjvYzdpCZV2tA8gwA_8bEkyNfghg',
user_agent='ImportanceAsleep6865',
)
subreddit = reddit.subreddit("cryptocurrency")
query = "Terra OR Luna"
search_results = subreddit.search(query, limit=2000)
# time range(2021.1 - 2022.6)
start_timestamp = int(datetime.datetime(2019, 1, 1).timestamp()) # 2019-01-01
end_timestamp = int(datetime.datetime(2022, 6, 30).timestamp()) # 2022-06-30
# filter and save to DataFrame
filtered_posts = {"Title": [], "Post URL": [], "Created At": []}
for post in search_results:
if start_timestamp <= post.created_utc <= end_timestamp:
filtered_posts["Title"].append(post.title)
filtered_posts["Post URL"].append(post.permalink)
filtered_posts["Created At"].append(datetime.datetime.fromtimestamp(post.created_utc))
# convert to Pandas DataFrame
df = pd.DataFrame(filtered_posts)
print(df.head())
df.to_csv("terra_luna_posts.csv", index=False, encoding="utf-8")
print(f" There are {len(df)} of post satisified the requirement and saved to terra_luna_posts.csv")
Then we created visualizations including word clouds that reveal common themes and concerns among community members. This is important for us as we might have to filter based on themes/words which comments in the dataset are actually relevant.
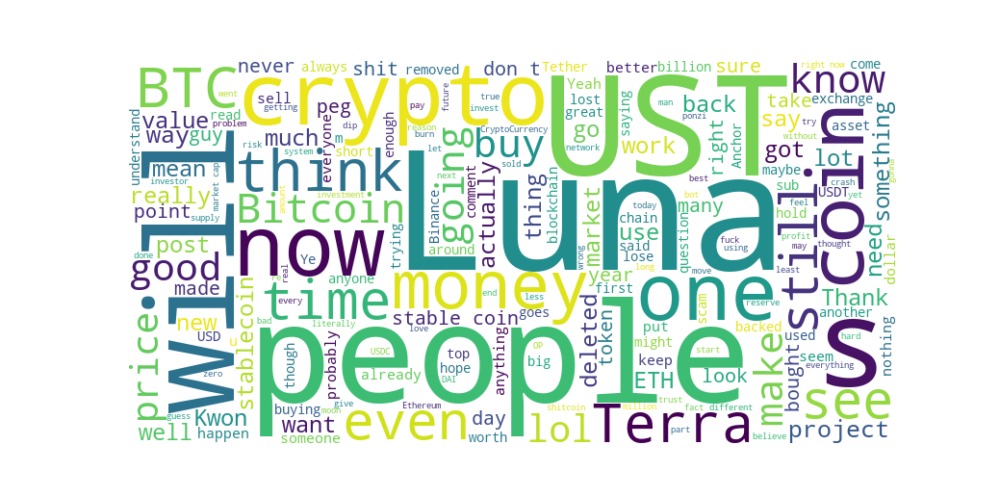
Words like "lost," "deleted," "shit," "ponzi," and "scam" indicate negativity, possibly referring to financial losses or scams."Good," "great," and "better" suggest some positive views, but they are relatively smaller. Frequent mentions of "money," "price," "value," and "market" indicate concerns about investment performance.Words like "buy," "sell," "risk," "stable," and "USD" imply discussions about trading, stability, and financial decisions. We've also compiled historical price-volume data to correlate with our sentiment metrics.
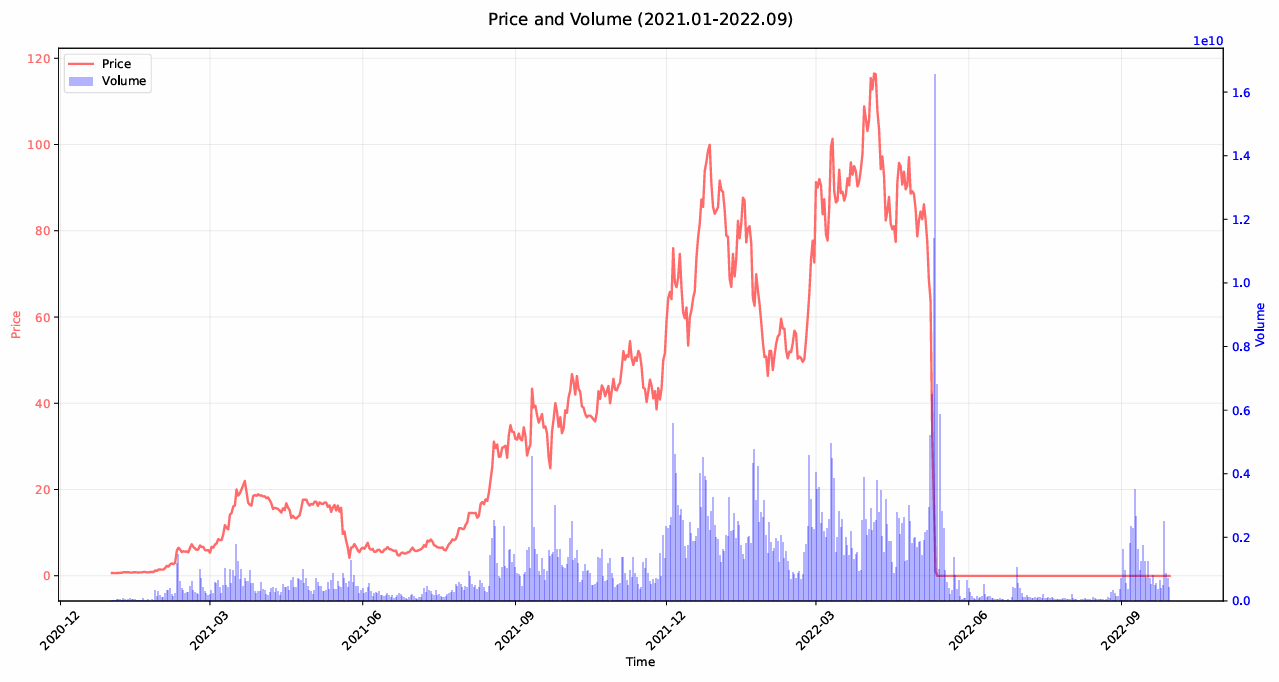
Based on this figure, we can see the price surge and fall of Terra Luna. The price experienced a significant rise from early 2021, peaking around late 2021 or early 2022. After reaching its peak, the price exhibited some volatility but remained high until mid-2022. A sharp and dramatic collapse occurred around mid-2022, where the price dropped to near zero and remained flat afterward. Trading volume fluctuated throughout the period, with occasional spikes corresponding to price movements.There was a massive spike in trading volume around the time of the price crash, indicating panic selling or forced liquidations.After the collapse, trading volume also significantly decreased, suggesting reduced interest or market activity.
Initial tests using our dictionary method have yielded intriguing but statistically insignificant results:
We started off simple by just calculating a negativity score for each comment, based on the classification of the Loughran-McDonald Dictionary. We then aggregated and averaged those scores for each day and compared it to the price movement.
import kagglehub
import pandas as pd
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt_tab') # For tokenization
import ast # For safely parsing string lists
# Step 1: Load Loughran-McDonald Dictionary
lm_dict = pd.read_csv('Loughran-McDonald_Dictionary.csv')
# Extract negative words (where 'Negative' column > 0)
negative_words = lm_dict[lm_dict['Negative'] > 0]['Word'].str.lower().tolist()
print(f"Loaded {len(negative_words)} negative words from LM Dictionary")
# Step 2: Load the test dataset from BTC.csv
# Replace 'BTC.csv' with your actual file path if different
headlines_df = pd.read_csv('BTC.csv')
# Step 3: Define sentiment scoring function
def get_lm_negativity_score(text):
# Tokenize the headline into words
words = word_tokenize(text.lower())
total_words = len(words)
# Count negative words
neg_count = sum(1 for word in words if word in negative_words)
# Calculate negativity score (proportion of negative words)
if total_words == 0:
return 0
return neg_count / total_words # Range: 0 to 1 (higher = more negative)
'''[# Step 4: Function that applies "get_lm_negativity_score" on each comment]'''
# Step 5: Calculate daily average negativity score
# Convert Comment Time to datetime and extract date only
comments_df['Comment Date'] = pd.to_datetime(comments_df['Comment Time']).dt.date
daily_negativity = comments_df.groupby('Comment Date')['negativity_score'].mean().reset_index()
daily_negativity.rename(columns={'negativity_score': 'avg_negativity_score'}, inplace=True)
# Step 6: Load price data
# Replace 'terra-historical-day-data-all-tokeninsight.csv' with your actual file path
price_df = pd.read_csv('terra-historical-day-data-all-tokeninsight.csv')
# Step 7: Merge daily negativity scores with price data
# Ensure date formats match (convert price Date to date)
price_df['Date'] = pd.to_datetime(price_df['Date']).dt.date
merged_df = pd.merge(daily_negativity, price_df, left_on='Comment Date', right_on='Date', how='left')
'''[...]'''
→ Our first trial analyzing all Reddit comments produced an R-squared value of only 0.003
These preliminary result suggested that our approach requires refinement. We did two smaller adjustments:
a) Cutting off post-crash data in the regression analysis, as it might be insignificant noise at a time when the price is not really moving anymore:
import pandas as pd
import statsmodels.api as sm
# Step 1: Load the Excel file with merged data
# Replace 'daily_negativity_and_prices.xlsx' with your actual file path if different
input_file = 'daily_negativity_and_prices.xlsx'
df = pd.read_excel(input_file)
# Step 2: Set timeframe (replace with desired start and end dates)
start_date = pd.to_datetime('2022-01-01').date() # Example start date
end_date = pd.to_datetime('2022-05-15').date() # Example end date | important: cutoff after crash
# Filter data based on timeframe
df = df[(pd.to_datetime(df['Comment Date']).dt.date >= start_date) &
(pd.to_datetime(df['Comment Date']).dt.date <= end_date)]
# Step 3: Prepare the data for regression
# Independent variable(s): avg_negativity_score
# Dependent variable: Price
X = df[['avg_negativity_score']] # Independent variable
X = sm.add_constant(X) # Add a constant term for the intercept
y = df['Price'] # Dependent variable
# Step 4: Run multiple regression
model = sm.OLS(y, X).fit()
# Step 5: Display regression results
print("\nMultiple Regression Results:")
print(model.summary())
b) Filtering the comments to make it more likely that they are actually about TerraLuna and not only Bitcoin or completely different topics:
import pandas as pd
# Step 1: Load the Excel file with Reddit comments
# Replace 'reddit_comments.xlsx' with your actual file path
comments_df = pd.read_excel('reddit_selected_rows.xlsx')
# Step 2: Transform data to filter comments containing "terra" or "luna" (case-insensitive)
def filter_terra_luna_comments(df):
return df[df['Comment Text'].str.contains('terra|luna', case=False, na=False)].copy()
filtered_comments_df = filter_terra_luna_comments(comments_df)
# Step 3: Save to a new Excel file
filtered_comments_df.to_excel('filtered_reddit_selected_rows.xlsx', index=False)
print("\nResults saved to 'filtered_reddit_selected_rows.xlsx'")
→ Still, our second trial with selected comments similarly showed an R-squared of 0.003
Hence, we currently have further adjustments in mind:
- Trying to use a multiple discriminant analysis: calculating scores for every category of the Loughran-McDonald Dictionary and finding out which (combination of) categories is/are the most accurate predictor of price
- Weighting comments based on community engagement (upvotes/downvotes)
- Incorporating time lag analysis through cross-correlation to identify delayed effects
After getting the most out of the simple dictionary method, we will try to move on to a deep learning architecture.
Technical Challenges and Lessons Learned
One significant challenge we've encountered is distinguishing meaningful signals from noise in social media data. Cryptocurrency communities can be particularly reactive and emotional, making sentiment analysis complex.
We've learned that simple correlation between sentiment scores and price movements doesn't capture the full relationship. Market dynamics likely involve multiple time scales and feedback loops that require more sophisticated modeling approaches.
Next Steps
Our team has established a detailed timeline for completing remaining tasks:
- Refine our data collection processes
- Improve our dictionary-based sentiment analysis model
- Develop and train our deep learning model
- Compare performance of both approaches
- Document findings and prepare presentation
We're particularly excited about implementing cross-correlation analysis to better understand temporal relationships between sentiment shifts and price movements.
Reflections on the Process
We learned a lot in the first weeks of working on the project. The most striking lessons are:
-
It is not easy at all to simply try to predict a price based on the sentiment. The initial major question that comes up is: is sentiment an accurate predictor of price? And if it is, it might still be very hard to get an accurate picture of the sentiment, that is, choosing the “right” sentiment data. Maybe people on Reddit are not moving the price, as they represent only small amounts of money. Is their thought actually relevant? If not, can we actually get the sentiment of those people who are moving the price? Either way, sentiment might still be lagging the price instead of predicting it. This is important to consider for further analysis. We are not only trying to make work something that does work for sure, but we also have to find out if it can work in the first place.
-
While the knowledge we learn in this course and the existing Python libraries are of much help in the code work, the real work is still done by getting more familiar with statistical thinking. The issue so far was not to put an idea of a method to work, but rather to find the right method for our case. It was easy for us to calculate negativity scores and get sentiment data, but it turned out to be difficult to make the most of that data, as there are endless methods we could apply to it. Therefore, we saw the need to actually understand what is going on under the hood of the Python libraries we are using. We ran a polynomial-regression method to determine the correlation of the negativity scores and price, but it could well be that only extreme negativity scores are correlating with sharp price movements, and that everything else is simple noise. This would require a completely different model than a polynomial regression to predict price movements.
-
Spending time together and doing regular meetings is absolutely essential and has helped us a lot. Since the beginning of the Semester, we met up almost every week and already developed a lot of great ideas together we probably would have not come up with alone. We also managed to distribute work effectively and are therefore confident that together we will be able to develop a model with more significant predictive power in the coming weeks.
Conclusion
Our project represents an ambitious attempt to bridge the gap between qualitative online discourse and quantitative market outcomes. Though we haven't yet discovered a reliable predictive relationship, our exploration has yielded valuable insights into both the technical challenges of sentiment analysis and the complex dynamics of cryptocurrency markets.
We welcome feedback and suggestions as we continue to refine our approach and explore this fascinating intersection of technology and finance.
References
Forbes. (2022, September 20). What Really Happened To LUNA Crypto? Forbes. https://www.forbes.com/sites/qai/2022/09/20/what-really-happened-to-luna-crypto/
Lee, S., Lee, J., & Lee, Y. (2022). Dissecting the Terra-LUNA crash: Evidence from the spillover effect and information flow. Finance Research Letters, 53(1544-6123). https://doi.org/10.1016/j.frl.2022.103590